
隐藏场景理解(CSU)是计算机视觉领域的一个研究热点,旨在对伪装物体进行感知。当前在技术和应用方面的繁荣需要进行最新的调查。这可以帮助研究人员更好地了解全球CSU领域,包括当前的成就和仍然存在的挑战。本文有以下四个方面的贡献:(1)我们首次提出了针对CSU的深度学习技术的全面调查,包括分类、特定任务的挑战和正在进行的发展。(2)为了对最先进的技术进行权威的量化,我们为隐藏目标分割(COS)提供了最大和最新的基准。(3)为了评估深度CSU在实际场景中的泛化性,我们收集了最大的隐藏缺陷分割数据集CDS2K,并在此基础上构建了综合基准。(4)讨论了CSU有待解决的问题和潜在的研究方向。
隐蔽场景理解(CSU)旨在识别表现出不同伪装形式的物体,如图1所示。就其本质而言,与传统的目标检测相比,CSU显然是一个具有挑战性的问题[1,2]。它在现实世界中有许多应用,包括搜救工作、稀有物种发现、医疗保健(如结肠直肠息肉[3,4]和肺部病变[5]的自动诊断)、农业(如害虫鉴定[6]和水果成熟度评估[7])和内容创作(如娱乐艺术[8])。在过去的十年中,学术界和工业界都对CSU进行了广泛的研究,并且使用传统的计算机视觉和模式识别技术处理了具有伪装物体的各种类型的图像,包括手工设计的模式(例如,运动线索[9,10]和光流[11,12]),启发式先验(例如,颜色[13],纹理[14]和强度[15,16])以及技术组合[17-19]。

隐藏案件样本库。(a) - (d)为动物在自然栖息地的图像,选自[20]。(e)在[21]的艺术作品中描绘了一个隐藏的人。(f)由[22]合成的“狮子”。
近年来,由于基准的出现(如COD10K[20,23]和NC4K[24])以及深度学习的快速发展,该领域取得了重要的进步。2020年,Fan等人[20]发布了第一个大规模公共数据集COD10K,旨在推进必须处理隐藏的感知任务。这也启发了其他相关学科。例如,Mei等人[25,26]提出了一种用于伪装物体分割的分心感知框架,该框架可扩展到自然场景中透明材料的识别[27]。2023年,Ji等人[28]开发了一种从对象级梯度中学习纹理的高效模型,并通过医疗息肉分割和道路裂缝检测等多种下游应用验证了其泛化性。
尽管多个研究团队已经解决了与隐藏物体有关的任务,但我们相信,在正在进行的努力之间进行更强的互动将是有益的。因此,我们主要回顾了基于CSU的深度学习的现状和最新进展。同时,我们提供了一个大规模的隐藏缺陷分割数据集CDS2K。该数据集由来自不同工业场景的硬案例组成,从而为CSU提供了有效的基准。
据我们所知,只有少数调查论文在CSU社区发表,[29,30]主要回顾了非深度学习技术。有一些基准[31,32]的范围很窄,例如图像级分割,其中只有少数深度学习方法被评估。在本文中,我们提出了深度学习CSU技术的全面调查,从而扩大了范围。我们还提供更广泛的基准与更全面的比较和面向应用的评估。
我们的贡献总结如下:(1)我们代表了彻底研究针对CSU量身定制的深度学习技术的初步努力。这包括对其分类和具体障碍的概述,以及通过对现有数据集和技术的检查来评估其在深度学习时代的进步。(2)为了对当前的技术水平进行定量评估,我们创建了一个新的隐藏目标分割(COS)基准,这是CSU中一个至关重要且非常成功的领域。它是最新和最全面的基准。(3)为了评估CSU与深度学习在现实场景中的适用性,我们重构了CDS2K数据集——隐藏缺陷分割的最大数据集——以包括来自各种工业环境的挑战性案例。我们利用这个更新的数据集创建了一个全面的评估基准。(4)我们的讨论深入到目前的障碍,可用的前景,并为CSU社区未来的研究领域。
在本节中,我们将介绍五个常用的图像级CSU任务,这些任务可以表示为将输入空间X转换为目标空间Y的映射函数。
?隐藏对象分割(COS)[23,28]是一种类别不可知的密集预测任务,它将类别未知的隐藏区域或对象分割。如图2(a)所示,模型由二值掩模Y监督,预测图像x的每个像素x的概率,这是模型确定x是否属于隐藏区域的置信度。

典型CSU任务的说明。其中五个是图像级任务:(a)隐藏目标分割(COS), (b)隐藏目标定位(COL), (c)隐藏实例排序(CIR), (d)隐藏实例分割(CIS), (e)隐藏目标计数(COC)。其余两个是视频级任务:(f)视频隐藏目标检测(VCOD)和(g)视频隐藏目标分割(VCOS)。每个任务都有自己相应的注释可视化,这将在2.1节中详细解释
?隐藏物体定位(hidden object localization, COL)[24,33]旨在识别隐藏物体最显眼的区域,这符合人类的感知心理[33]。这个任务是学习一个密集映射函数。输出Y是眼动仪捕获的非二值注视图,如图2(b)所示。从本质上讲,对像素x的概率预测表明了它的伪装有多明显。
?隐藏实例排名(CIR)[24,33]根据可探测性对隐藏场景中的不同实例进行排名。伪装水平是这个排名的基础。CIR任务的目标是学习输入空间X和伪装排名空间Y之间的密集映射,其中Y表示具有相应排名水平的每个实例的逐像素注释。例如,在图2(c)中,有3只蟾蜍具有不同的伪装等级,它们的等级标签来自[24]。为了完成这项任务,可以在Mask R-CNN[34]等实例分割模型中,将每个实例的类别ID替换为等级标签。
?隐藏实例分割(CIS)[35,36]是一种基于语义特征识别隐藏场景中的实例的技术。与一般的实例分割不同[37,38],其中每个实例被分配一个类别标签,CIS识别隐藏对象的属性以更有效地区分不同的实体。为了实现这一目标,CIS使用了一个映射函数,其中Y是一个标量集,包含用于解析每个像素的各种实体。这个概念如图2(d)所示。
?隐藏对象计数(COC)[39]是CSU中一个新兴的主题,旨在估计隐藏在其周围环境中的实例数量。如图2(e)所示,COC估计每个实例的中心坐标并生成它们的计数。其表达式可以定义为,其中X为输入图像,Y为输出密度图,表示场景中隐藏的实例。
总的来说,映像级CSU任务可以根据其语义分为两组:对象级(COS和COL)和实例级(CIR、COC和CIS)。对象级任务侧重于感知对象,而实例级任务侧重于识别语义以区分不同的实体。此外,根据COC的输出形式,将其视为稀疏预测任务,而其他都属于密集预测任务。在表1所回顾的文献中,COS已经得到了广泛的研究,而其他三个任务的研究也在逐渐增加。
给定包含T个隐藏帧的视频片段,视频级CSU可以表示为解析密集时空对应的映射函数,其中为帧的标签。
?视频隐藏目标检测(Video hidden object detection, VCOD)[40]与视频目标检测[41]类似。该任务旨在通过学习时空映射函数来识别和定位视频中的隐藏物体,该函数可以预测每帧物体的位置。位置标签以包围框的形式提供(见图2(f)),包含四个数字,表示目标的位置。其中,表示其左上角坐标,w和h分别表示其宽度和高度。
?视频隐藏对象分割(Video hidden object segmentation, VCOS)[42]源于伪装对象发现任务[40]。它的目标是在视频中分割隐藏的物体。该任务通常利用时空线索驱动模型学习输入帧与相应分割掩码标签之间的映射关系。图2(g)显示了其分割掩码的示例。
总的来说,与图像级CSU相比,视频级CSU的发展相对缓慢,因为视频数据的采集和标注是一项费时费力的工作。然而,随着MoCA-Mask上第一个大规模VCOS基准的建立[42],该领域取得了根本性的进展,但仍有很大的探索空间。
在图像级CSU任务中,CIR任务对理解水平的要求最高,因为它不仅涉及像素级区域分割(COS)、计数(COC)或区分不同实例(CIS)等四个子任务,而且还需要根据不同难度下的固定概率(COL)对这些实例进行排序。此外,对于两个视频级任务,VCOS是VCOD的下游任务,因为分割任务需要模型提供像素级分类概率。
接下来,我们将简要介绍显著目标检测(SOD),它与COS一样需要提取目标对象的属性,但一个侧重于显著性,而另一个侧重于隐藏属性。
?图像级SOD旨在识别图像中最吸引人的物体,并提取其像素级精确的轮廓[43]。在深度SOD模型中已经探索了各种网络架构,例如多层感知器[44-47]、全卷积[48-52]、基于胶囊的[53-55]、基于变压器的[56]和混合[57,58]网络。同时,SOD模型中也研究了不同的学习策略,包括数据高效方法(如使用分类标签的弱监督方法[59-63]和使用伪掩码的无监督方法[64-66])、多任务范式(如使用对象细分[67,68]、注视预测[69,70]、语义分割[71,72]、边缘检测[73-77]、图像字幕[78])和实例级范式[79-82]。为了更全面地了解这一领域,读者可以参考一些流行调查或有代表性的研究,如视觉注意[83]、显著性预测[84]、共显著性检测[85-87]、RGB SOD[1,88 - 90]、RGB- d(深度)SOD[91,92]、RGB- t(热)SOD[93,94]、光场SOD[95]等。
?视频级SOD。视频显著目标检测的早期发展源于在视频目标分割(VOS)任务中引入注意机制。在那个阶段,任务场景相对简单,在视频中只包含一个移动的物体。由于运动物体容易引起视觉注意,因此VOS和VSOD是等效的任务。例如,Wang等人[96]使用全卷积神经网络来解决VSOD任务。随着VOS技术的发展,研究人员引入了更复杂的场景(如复杂背景、物体运动和两个物体),但两个任务仍然是等效的。因此,后来的研究利用了语义级时空特征[97-100]、循环神经网络[101,102]或离线运动线索,如光流[101,103-105]。然而,随着更具挑战性的视频场景(包含三个或更多物体,同时摄像机和物体运动)的引入,VOS和VSOD不再等效。然而,研究人员仍然将这两个任务等同对待,忽视了视频场景中多目标运动中的视觉注意分配问题,严重阻碍了该领域的发展。为了解决这一问题,2019年,Fan等[106]引入眼动仪来标记多目标运动场景下视觉注意力的变化,首次提出了VSOD任务中注意力转移的科学问题,并构建了第一个大规模VSOD基准——DAVSOD,Footnote 1以及基线模型SSAV,将VSOD推进到一个新的发展阶段。
?言论。COS和SOD是不同的任务,但它们可以通过CamDiff方法相互受益[107]。这已经通过对抗性学习[108]得到了证明,导致了最近提出的二分类图像分割[109]等联合研究努力。在第6节中,我们将探讨这些领域未来研究的潜在方向。
本节系统地回顾了基于任务定义和数据类型的CSU深度学习方法。我们还创建了一个GitHub baseFootnote 2作为一个全面的集合,以提供该领域的最新信息。
我们回顾了现有的四种图像级CSU任务:隐藏目标分割(COS)、隐藏目标定位(COL)、隐藏实例排序(CIR)和隐藏实例分割(CIS)。表1总结了这些方法的主要特点。
本节从网络架构和学习范式两个角度讨论了伪装对象分割(COS)的先前解决方案。
?网络架构。一般来说,全卷积网络(fcn[150])是图像分割的标准解决方案,因为它可以接收灵活大小的输入,并进行单一的前馈传播。正如预期的那样,fcn形状的框架主导了COS的主要解决方案,它们分为三类:
(1)如图3(a)所示的多流框架包含多个输入流,以明确学习多源表示。MirrorNet[110]是第一次尝试添加额外的数据流作为生物启发攻击,可以打破伪装状态。最近的一些研究采用了多流方法来改进他们的结果,例如提供伪深度生成[149]、伪边缘不确定性[114]、对抗学习范式[108]、频率增强流[135]、多尺度[134]或多视图[141]输入,以及多个主干[147]。与其他监督设置不同,CRNet[142]是唯一使用潦草标签作为监督的弱监督框架。这种方法有助于缓解在有限的注释数据上的过拟合问题。
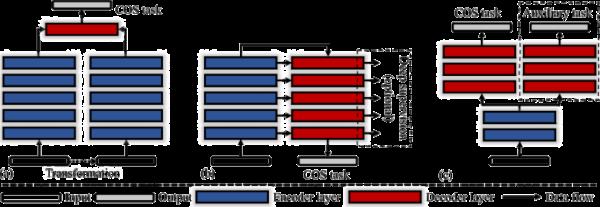
COS的网络架构一览。我们从左到右展示了四种类型的框架:(a)多流框架,(b)自下而上/自上而下框架及其具有深度监督的变体(可选),以及(c)分支框架。参见3.1.1节了解更多细节
(2)自底向上和自顶向下框架,如图3(b)所示,在单次前馈过程中,使用较深的特征逐步增强较浅的特征。例如,C2FNet[113]采用这种设计,从粗到细的层次改进隐藏特征。此外,segar[136]采用了基于该策略的迭代细化网络和子网。此外,其他研究[20,23,25,26,112,118 - 121,124,125,129,138 - 140,143 - 145,148]使用该框架对各种中间特征层次使用深度监督策略[151,152]。特征金字塔网络也采用了这种做法[153],通过密集的自顶向下和自底向上传播,结合了更全面的多上下文特征,并在最终预测之前引入额外的监督信号,为更深层提供更可靠的指导。
(3)分支框架,如图3(c)所示,是一种单输入多输出架构,由分段和辅助任务分支组成。需要注意的是,该分支框架的分割部分可能与之前的框架有一定的重叠,如单流[21]和自底向上和自顶向下[24、28、33、108、111、115-117、122、123、125-128、130-133、137]框架。例如ERRNet[123]和FAPNet[127]就是联合学习隐藏对象及其边界的典型例子。由于这些分支框架与多任务学习范式密切相关,我们将提供进一步的细节。
?学习范式。我们讨论了COS任务的两种常见学习范式:单任务和多任务。
(1)单任务学习是COS中最常用的范式,它只涉及对隐藏目标的分割任务。基于这一范式,目前大多数研究[20,23,121]都侧重于开发注意力模块来识别目标区域。
(2)多任务学习引入辅助任务来协调或补充分词任务,实现鲁棒COS学习。这些多任务框架可以通过执行伪装对象的置信度估计[108,117,130,132]、定位/排序[24,33]、类别预测[21]任务和学习深度[111,149]、边界[116,122,123,126,127,131]和纹理[28,115]线索来实现。
关于这个话题的研究很有限。Lv等人[24]首次观察到现有COS方法无法量化伪装的难度等级。针对这个问题,他们使用眼动仪创建了一个新的数据集,称为CAM-LDR[33],其中包含实例分割掩码、固定标签和排名标签。他们还提出了两个统一的框架LSR[24]及其扩展LSR+[33],用于同时学习伪装对象的定位、分割和排序三重任务。其背后的思想是,判别定位区域可以指导对全范围伪装目标的分割,然后通过排序任务来推断不同伪装目标的可检测性。
该任务将COS任务从区域级推进到实例级,与COS相比,这是一个相对较新的领域。然后,Le等[36]通过扩展之前的CAMO[21]数据集,构建了一个新的CIS基准,CAMO++。他们还提出了一种伪装融合学习策略,通过学习图像上下文来微调现有的实例分割模型(例如Mask R-CNN[34])。基于COD10K[20]和NC4K[24]等实例基准,针对该领域提出了第一个一级变压器框架OSFormer[35],引入了两个核心设计:位置传感变压器和粗精融合。最近,Luo等人[146]提出了两种分割伪装实例的设计:像素级伪装解耦模块和实例级伪装抑制模块。
Sun等人[39]最近提出了一个新的挑战,称为不可分辨物体计数(IOC),它涉及对难以与其周围环境区分的物体进行计数。他们创建了IOCfish5K,这是一个大型数据集,包含水下场景的高分辨率图像,其中包含许多无法识别的物体(专注于鱼)和密集的注释,以解决缺乏合适的数据集来应对这一挑战。他们还提出了一个称为IOCFormer的基线模型,将基于密度的方法和基于回归的方法集成在一个统一的框架中。
基于以上总结,COS任务正处于快速发展期,每年都有大量的当代出版物。然而,针对COL、CIR和CIS任务提出的解决方案很少。这表明这些领域仍未得到充分开发,并为进一步研究提供了重要的空间。值得注意的是,许多先前的研究可以作为参考(如显著性预测[84]、显著性对象细分[68]和显著性实例分割[82]),为从伪装的角度理解这些任务提供了坚实的基础。
视频级CSU任务有两个思想流派,包括从视频中检测和分割伪装对象。详见表2。
大多数作品[156,158]将该主题表述为由于像素级注释的稀缺性而导致分割任务的退化问题。像往常一样,它们在分割数据集(例如DAVIS[161]和FBMS[162])上进行训练,但在视频伪装目标检测数据集MoCA[40]上评估了泛化性能。这些方法一致地选择提取离线光流作为分割任务的运动引导,但它们在学习策略上有所不同,例如使用真实[40,157,160]或合成[155,158]数据的全监督学习和自监督学习[156,159]。
Xie等人[154]提出了视频中伪装对象发现的第一项工作。他们使用像素轨迹递归神经网络对前景运动进行聚类分割。然而,这项工作仅限于小规模数据集CAD[163]。最近,Cheng等人[42]在带有边界框标签的定位级数据集MoCA[40]的基础上,扩展了这一领域,创建了带有像素级掩码的大规模VCOS基准MoCA- mask。他们还引入了一个两阶段基线SLTNet来隐式地利用运动信息。
从我们上面回顾的内容来看,目前VCOS任务的方法仍处于发展的初级阶段。在成熟的视频分割领域(例如,自监督对应学习[164-168],不同基于动作的任务的统一框架[169-171])的几个并行工作指出了进一步探索的方向。此外,考虑到高级语义理解还有一个值得补充的研究空白,如伪装场景中的语义分割和实例分割。
近年来,图像级和视频级CSU任务收集了各种数据集。在表3中,我们总结了代表性数据集的特征。
?CAMO- coco[21]是为COS任务量身定制的,包含8个类别的2500个图像样本,分为两个子数据集,即具有伪装对象的CAMO和具有非伪装对象的MS-COCO。CAMO和MS-COCO都包含1250张图像,其中1000张用于训练,250张用于测试。
?NC4K[24]是目前评估COS模型的最大测试集。它由4121张来自互联网的伪装图像组成,可分为两大类:自然场景和人工场景。除了图像之外,该数据集还提供了包含对象级分割和实例级掩码的定位标签,使其成为该领域研究人员的宝贵资源。在Lv等人[24]最近的一项研究中,使用眼动仪收集每张图像的注视信息。因此,创建了一个包含2280张图像的CAM-FR数据集,其中2000张用于训练,280张用于测试。数据集用三种类型的标签进行注释:本地化、排名和实例标签。
?CAMO++[36]是一个新发布的包含5500个样本的数据集,所有样本都经过了分层像素级标注。数据集分为两部分:伪装样本(1700张用于训练,1000张用于测试)和非伪装样本(1800张用于训练,1000张用于测试)。
?COD10K[20,23]是目前规模最大的数据集,具有广泛的伪装场景。它包含来自多个开放访问摄影网站的10,000张图片,涵盖10个超类和78个子类。在这些图片中,有5066张是伪装图片,1934张是非伪装图片,3000张是背景图片。COD10K的伪装子集使用不同的标签(如类别标签、边界框、对象级掩码和实例级掩码)进行注释,从而提供不同的注释集。
?CAM-LDR[33]由4040个训练样本和2026个测试样本组成。这些样本是从常用的混合训练数据集(即CAMO有1000个训练样本,COD10K有3040个训练样本)和测试数据集(即COD10K有2026个测试样本)中选择的。CAM-LDR是NC4K的扩展[24],包括四种类型的注释:本地化标签、排名标签、对象级分割掩码和实例级分割掩码。排名标签分为6个难度等级:背景、简单、中等、中等、中等、中等和困难。
?S-COD[142]是第一个专门为弱监督设置下的COS任务设计的数据集。数据集包括4040个训练样本,其中COD10K中选择3040个样本,CAMO中选择1000个样本。这些样本使用潦草的注释重新标记,这些注释提供了基于第一印象的主要结构的大致轮廓,没有像素级的真实信息。
?IOCfish5K[39]是一个独特的数据集,专注于在伪装场景中计算鱼的实例。该COC数据集包括来自YouTube的5637张高分辨率图像,其中659,024个中心点进行了注释。数据集被分为三个子集,其中3137张图像用于训练,500张用于验证,2000张用于测试。
总之,三个数据集(CAMO, COD10K和NC4K)通常被用作评估伪装目标分割(COS)方法的基准,实验协议通常在5.2节中描述。对于隐藏实例分割(CIS)任务,可以使用包含实例级分割掩码的两个数据集(COD10K和NC4K)。CAM-LDR数据集提供了固定信息和从物理眼动仪设备收集的三种类型的注释,适用于各种大脑启发的计算机视觉探索。此外,还有两个来自CSU的新数据集:S-COD,专为弱监督COS设计,以及IOCfish5K,专注于计算伪装场景中的物体。
?CAD[163]是一个小数据集,包括9个短视频剪辑和836帧。该数据集使用的标注策略是稀疏的,每五帧对伪装对象进行标注。结果,数据集中有191个可用的分割掩码。
?MoCA[40]是一个来自YouTube的综合视频数据库,旨在检测移动的伪装动物。它由141个视频片段组成,具有67个类别,包括37,250个高分辨率帧,具有7617个实例的相应边界框标签。
?MoCA- mask[42]是MoCA数据集[40]的扩展,基于MoCA数据集[40],每5帧提供人工注释的分割掩码。MoCA-Mask分为两部分:由71个短片段(19,313帧,3946个分割掩码)组成的训练集和包含16个短片段(3626帧,745个分割掩码)的评估集。为了标记那些未标记的帧,使用基于双向光流的策略合成伪分割标签[172]。
MoCA数据集是目前最大的隐藏对象视频集合,而它只提供检测标签。因此,社区中的研究人员[156,158]通常通过将分割掩码转换为检测边界框来评估训练良好的分割模型的性能。最近,随着MoCA-Mask的引入,在隐蔽场景中出现了视频分割的转变。尽管取得了这些进步,但数据注释的数量和质量仍然不足以构建可靠的视频模型,从而有效地处理复杂的隐藏场景。


发表评论
暂时没有评论,来抢沙发吧~